Side projects make the engineer

There’s a specific type of person I’ve noticed applying to jobs, participating in ML communities, or writing to me online: software engineers with an interest in machine learning. Their ML background typically consists of a course or two from Andrew Ng, and perhaps a few other MOOCs.
This trend is great: the world is short of experienced machine learning engineers so it’s good to see more people entering the field. However, simply watching video lectures is not enough to be productive as an engineer, and the people hiring for ML positions know that.
Since a theoretical background isn’t enough to get hired, you need to have experience applying ML to practical problems. Experience is built by solving someone’s problems with ML – which means getting hired. This circular dependency can be really frustrating.
The chicken-egg problem also exists in other fields. Fortunately the solution is also found in a neighboring discipline: software engineers have long been showing off their prowess in side projects, and aspiring machine learning engineers can too.
Side projects make you stand out
When evaluating someone’s skill in applying ML I use the obvious criterion of “have they previously built a machine learning system that works well”. For software-engineers-with-an-interest that simplifies to “have they built an ML side project”. Kaggle competitions are also a signal, though weaker because they are too neatly fed to participants with a clear problem setup, evaluation criteria, data annotations and extracted dataset.
Surprisingly, very few people can show interesting side projects. I can think of two reasons. First, it is difficult to come up with ideas that would be technically interesting and well-motivated (i.e. useful or cool). Second, there is a misunderstanding of what an ML (side) project entails. Let’s address the misunderstanding first.
Real-world machine learning is mostly not about training models
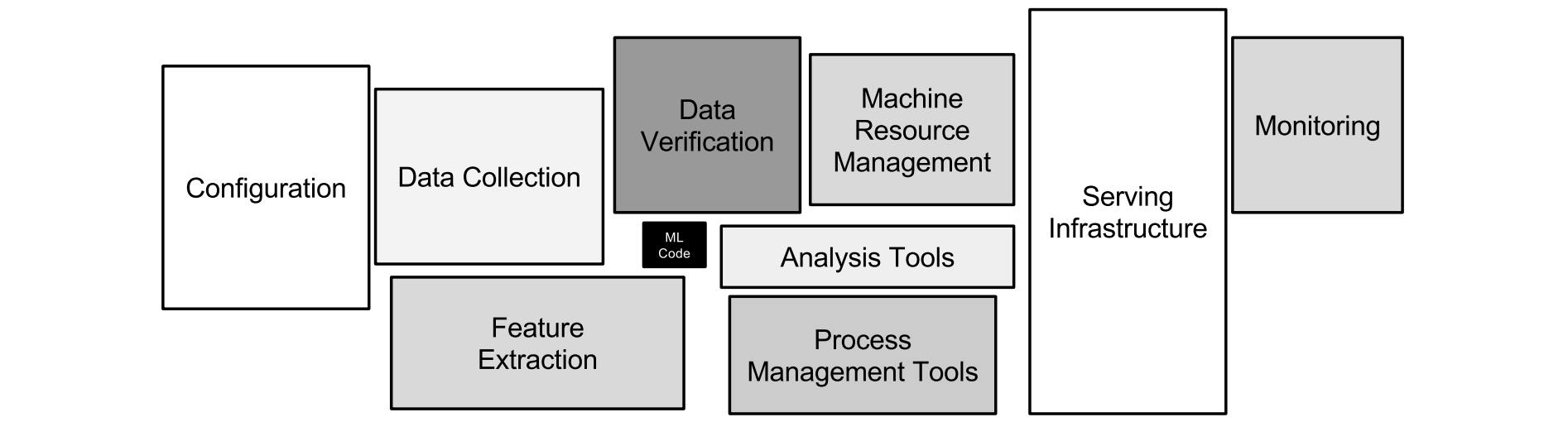
There is a great illustration in Hidden Technical Debt in Machine Learning Systems, a 2016 paper from Google:

Training models is only a tiny part of the effort needed to get an ML model to production. The other parts take significantly more time: understanding the business problem, formulating it as a supervised/unsupervised task, collecting and annotating data, handling infrastructure, etc.
Most MOOCs and university courses focus on model training and evaluation. Simply having worked on the tiny ML code part shows very little about your ability to work with the stack of components shown above. On the other hand, an interesting ML project typically requires you to collect, clean and annotate your own data; experiment with various features; understand where the model is working and where it isn’t; deploy and serve predictions; possibly build a front-end interface for the model.
Thus you should not make your ML side project only about training models. It is more valuable to show off all the other parts that will distinguish you from the people who just finished Andrew Ng’s “Machine Learning”.
With that in mind, let me give my rough recipe for building ML side projects.
- Find a useful or cool idea using some machine learning method you already know.
- Decide how you will evaluate the outcome quantitatively.
- Collect a dataset for evaluation (and training, if you can get enough data).
- Implement v1 of the system.
- Get a good understanding of what kinds of input the system fails on, and iterate.
Let me highlight two things.
First, collecting data is crucial: you could use publicly available datasets instead, but it is usually difficult to do anything novel on top of those. Object detection datasets are designed to be as general as possible and generality is boring. A side project on a global dataset of 1000 generic object classes is unlikely to be interesting; counting the number of pine trees on smartphone photos of Estonian forests is.
Second, evaluation and iteration: one of the most fruitful questions about ML systems is “where does it fail”. To answer you have to manually look at examples and try to generalise: e.g. “we often miss face detections where the face is partially in the shadow”. This way you can come up with next steps for improvement – something you’ll likely be asked in an interview, and asking yourself daily as a data scientist.
Project meta-ideas
A list of specific project ideas would not be relevant for long so I’ll instead give some ways to come up with project ideas.
- Think of interesting datasets you could automatically collect, and predictions you could make based on this dataset.
- Collect all images of IKEA furniture and try to generate new pieces specifically in their Scandinavian style.
- Collect all historical classified ads, do some topic modelling and figure out which sorts of patterns emerge over time.
- Collect images of people of specific groups, e.g. Estonian vs Finnish girls (#estoniangirl and similar hashtags are popular on Instagram). Build a classifier to distinguish people of one nationality from those of another, e.g. Estonian vs Finnish, or train a CycleGAN model to convert between them.
- If a problem is well-solved in general, it might still be interesting locally.
- Instead of building a general face detection system, try finding all politicians’ faces in all images published by the government.
- Predict local stock prices, local real estate value, or local demand for used cars.
- If you have a dataset but can’t think of a supervised learning problem, explore.
- Suppose you have the per-person voting history of the local parliament. You could learn an embedding for each member of parliament, cluster them in that space, and visualise.